[논문 정리] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Transformer Architecture와 GPT에 관한 논문을 읽고 난 후, 이 모델이 컴퓨터 비전에는 어떻게 적용되는지 궁금해졌다. 그래서 2020년 발표 당시 ResNet의 성능을 뛰어넘었던 Vision Transformer(ViT) 모델에 관한 논문을 읽어보기로 했다.
Background
Transformer의 출현으로 인해 NLP 분야의 패러다임이 완전히 바뀐 이후, 이 모델을 이미지 처리에도 적용하려는 여러 시도들이 있어 왔다. 이전에 제안된 모델들은 CNN 기반 모델에 Self Attention을 부분적으로 결합하는 방식으로 접근했는데, 하드웨어 가속기를 효율적으로 활용해 구현하기 어렵다는 문제점이 있었다. 이 논문에서는 CNN에 Self Attention을 일부 적용하는 대신, Transformer의 기본 구조를 최대한 바꾸지 않고 Vision 작업에 적용하여 SOTA를 달성했다.
Framework
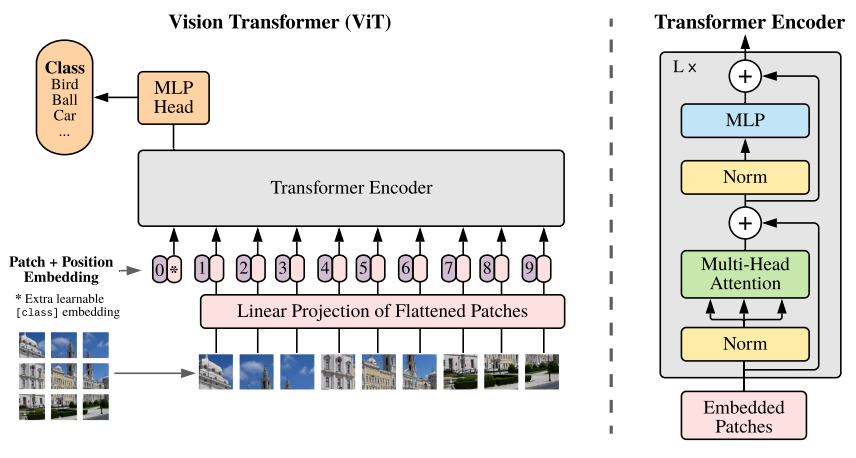
ViT는 우선 입력 이미지를 고정된 사이즈를 가진 여러 개의 patch들로 분할한다. 이들을 각각 임베딩으로 바꾼 후, patch의 위치 정보를 표시하는 Position Embedding과 결합해 Transformer Encoder의 입력으로 넣는다. Encoder는 Transformer 논문에서 제안된 구조와 거의 동일하다. 그 다음 Encoder의 출력으로 나온 결과물을 Classification 등 최종 과제를 수행할 Multi-Layer Perceptron의 입력으로 넣어, 최종적으로 원하는 결과를 얻게 된다.
수식으로 표현하면 다음과 같다.
()
입력 이미지를 패치로 나누어 각각 Embedding한 들에 Positional embedding을 더해 Encoder의 입력이 될 을 얻는다.
그리고 l = 1 ... L 에 대해 여러 층의 Encoder를 통과하는 과정은 위의 식으로 나타낼 수 있다. (LN=LayerNorm)
Encoder의 최종 출력은 위 식의 y이다. 이는 원래 이미지의 임베딩들에 대한 정보를 벡터 하나에 담은 'Representation'이라 볼 수 있다. y가 Classification 등 최종 과제를 수행하는 MLP의 입력으로 들어가게 되는 것이다. 이 식에서 Encoder의 출력 중 첫 번째 patch에 해당하는 만을 LayerNorm하여 y를 얻는 걸 알 수 있는데, 이 위치는 처음 식에서 다른 모든 패치들의 앞에 집어넣은 'class embedding' 에 해당하는 위치이다. (의 값도 trainable한 값이다. class embedding의 개념은 BERT 논문에서 제안되었다고 하니 이 부분을 더 알아보면 좋을 것 같다.)
ViT는 CNN 기반 모델과 다르게, 고정된 크기의 filter를 사용하지 않는다. 즉 이미지에서 하나의 Feature를 이루는 정보들은 이미지 상에서 서로 가까이 있다고 보는 Locality를 가정하지 않고 CNN보다 더 global한 위치 관계를 학습할 수 있다. 그러나 그만큼 사전학습에는 큰 규모의 데이터셋이 필요하다고 본 논문에서는 설명하고 있다.
Experiments
이 연구에서는 기존의 ResNet, ViT, 그리고 하이브리드 모델을 이용해 실험을 진행했다. (하이브리드 모델은 CNN의 출력인 Feature Map을 ViT 모델의 입력으로 받는 모델이다.) 해당 실험에서 ImageNet, CIFAR 등 데이터셋을 이용해 훈련시킨 결과 ViT 모델이 SOTA였던 ResNet을 능가함으로써 컴퓨터 비전 분야에 새로운 바람을 불어넣었다.
개인적으로 이 논문을 읽으면서 Transformer 모델에 Transformer라는 이름이 붙게 된 이유를 좀 더 깊게 이해하게 된 것 같다. 입력된 Embedding 속 부분들을 그 자신과 다른 부분들 사이의 관계가 반영된 representation으로 '변환'해준다는 의미에서 구글 연구자들이 이런 이름을 붙였다는 생각이 들었다.